Auf dem „OER IT Sommercamp“ steckten Entwickler*innen, Entscheider*innen, Projektmanager*innen und Konzepter*innen aus dem Schul- und Hochschulbereich ihren Kopf für zweieinhalb Tage in Weimar zusammen, um gemeinsame Konzepte, Projekte und Prototypen zu entwickeln. Auf der Agenda standen unter anderem die Weiterentwicklung der Einsatzmöglichkeiten von KI Technologien für Bildung, die Implementierung von OER förderlichen Schnittstellen in Tools und Services und gemeinsame Projekt-Abstimmung der Community.
Lightning-Talks
Auf jedem IT Camp können Teilnehmende die Inhalte und Schwerpunkte selbst mitgestalten. Eine Form davon sind Lightning-Talks, in denen Experten in 5-10 Minuten über ein bestimmtes Thema von allgemeiner Interesse berichten:
- Joachim Dieterich und Boris Bockelmann (Pädagogische Landesinstitut Rheinland-Pfalz), André Scherl (Mebis / ISB Bayern) und Henry Freye (Landesinstitut für Schule und Medien – Berlin/Brandenburg) stellten Aufbau und Struktur von (digitalen) Lehrplänen vor
- Robert Mischke schilderte aktuelle Überlegungen, wie Lernpfade und pädagogische Einordnungen in ihrem Tool „Memucho“ abgebildet werden können.
- Zum Schwerpunktthema „KI“ zeigten Ralph Ewert (TIB Hannover) und Torsten Simon (edu-sharing Network e.V.) Ergebnisse aus dem vergangenen Frühjahrscamp und nannten Ziele für den Workshop
- Steffen Hippeli und Matthias Hupfer (edu-sharing Network e.V.) stellten aktuelle OER Metadaten- und Schnittstellenkonzepte aus den Arbeitsgruppen und vergangenen Workshops vor
- Tobias Westphal (edu-sharing Network e.V.) stellte die aktuelle OER Demo-Umgebung vor und zeigte verfügbare Tools und Services, die der Community zum Testen bereitstehen.
Lehrpläne mit KI füllen (Workshop 2)
Ziel des KI-Workshops war es, Materialien mittels einer KI (Neuronales Netz, Algorithmus) in eine Lehrplan-Struktur einzusortieren.
Während des Workshops-Verlaufs haben wir festgestellt, dass der Aufwand einer Zuordnung recht hoch ist, auch weil die Lehrpläne in allen Bundesländern unterschiedlich sind. Daher haben wir im ersten Versuch uns zunächst darauf konzentriert, einzelne Feldzuordnungen (Metadaten, z.B. Sachgebiet, Schulfach) aus den Daten zu extrahieren, um neue Materialien automatisch diese Daten zuzuordnen. In einem weiteren Schritt wäre es auch denkbar, anhand dieser erzeugten Metadaten eine finale Zuordnung zum Lehrplan zu machen. Dies hätte den Vorteil, dass diese “Zwischendaten” einheitlich für alle Länder sein könnten, und nur die finale Zuordnung unterschiedlich aussehen müsste. Außerdem sind die Metadaten für das allgemeine Finden von Materialien hilfreich.
Wir hatten hierfür verschiedene Datensätze als Grundlage zur Verfügung, u.a. die Lehrplanstruktur Bayern mit etwa 38.000 Datensätze, der Lehrplan Rheinland-Pfalz mit etwa 15.800 Datensätzen sowie einen Pool an Materialien mit Metadaten (Sodis Content Pool) mit etwa 4.000 Datensätzen.
- Matthias Springstein (TIB Hannover) bereitete ein Tutorial zum Textmining vor und klassifizierte Daten. Er trainierte ein neuronales Netz mit Lehrplan-Daten und erhielt bei der automatischen Zuordnung der Inhalte in 98 Fachgebiete eine Genauigkeit von 22%.
- Daniel Rudolph und Torsten Simon (edu-sharing Network e.V.) beschäftigte sich mit dem „scikit-learn“ Framework und führte Tests zur Textklassifikation und Datenauswertung aus dem bayrischen Lehrplan vor
- Andre Scherl (Mebis – ISB Bayern) organisierte Lehrplandaten und half bei der Aufbereitung
- Viktor Eisenstadt (TIB Hannover) arbeitete an der Daten-Vorverarbeitung und Aufbereitung der Lehrpläne
- Torsten Simon beschäftigte sich mit der Datenaufbereitung aus dem SODIS Contentpool, führte Tests mit und ohne Stop-Words-Entfernung durch und baute einen Mini-Webservice mit dem man Textklassifikation in 5 Kategorien vornehmen kann.
OER Schnittstellen (Workshop 3+4)
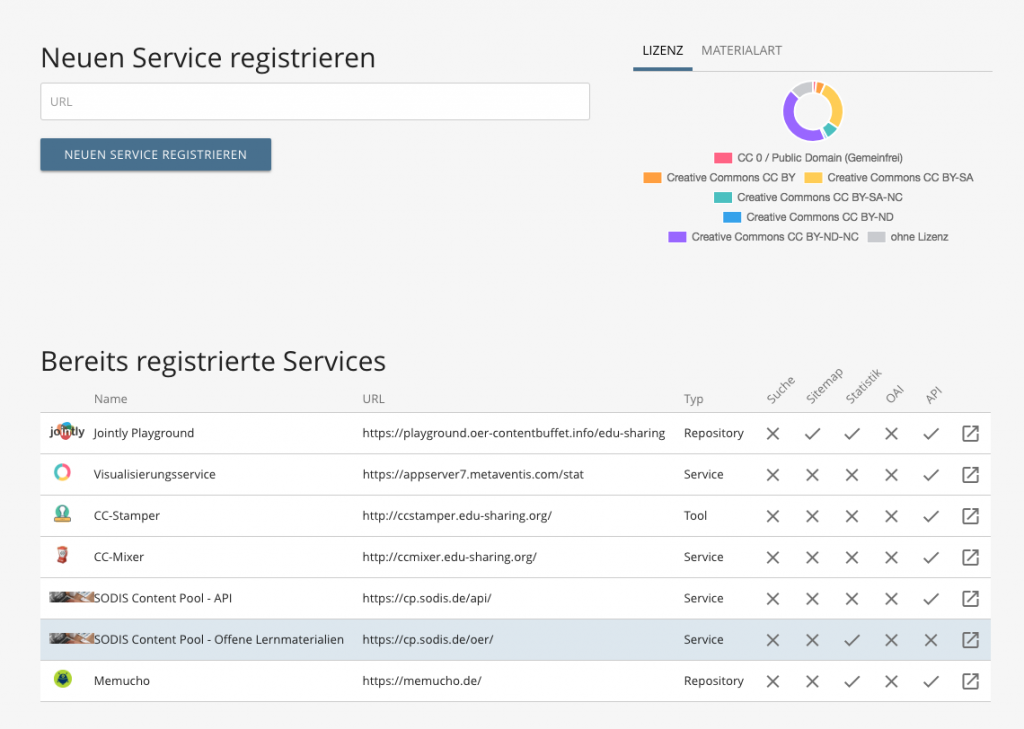
Ziel des Workshops war es, verschiedene Tools und Systeme mit OER förderlichen Schnittstellen aufzurüsten. Konkret konnte eine Visitenkarte des eigenen Services erstellt und für einen Statistikabruf bereitgestellt werden, der am OER-Playground installiert ist. Der zentrale Statistikservice zeigt dabei alle registrierten Tools mit technischen Informationen (z.B. ob eine API vorhanden ist) und gibt die Anzahl der Materialien und verwendeten Lizenzen aus.
Darüber hinaus wurden Metadaten für Suchmaschinen (LRMI) oder für föderierte Suchen an Repositorien integriert.
Statistikservice und Schnittstelle für OER Portal
Friedhelm Schumacher erstellte eine Visitenkarte des SODIS OER Portals und der zugehörigen API. Damit registrierte er die Umgebung am Statistikservice.
searX4OER
David „-1“ Schmid erweiterte die Metasuchmaschine ’searx‘ um Suchmaschinen, die frei
verfügbare Inhalte und deren Lizenzinformationen sammeln. Eingefügte Suchmaschinen sind:
vimeo, oerworldmap, wikimedia commons, memucho, tutory und pixabay.
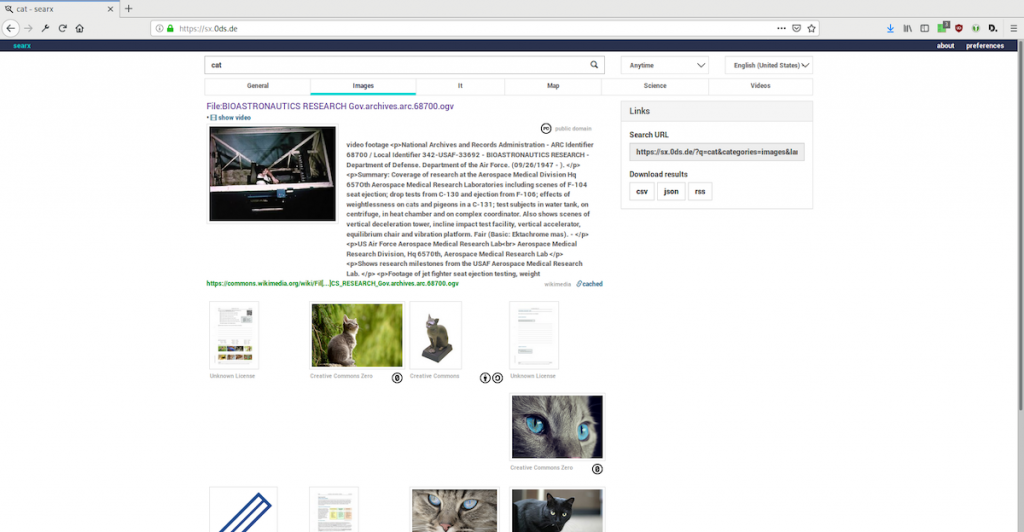
Der Prototyp kann hier getestet werden: https://sx.0ds.de/
Der Code ist hier zu finden: https://github.com/einsweniger/searx
Fiplor
Tom Adler stellte seine App „Fiplor“ vor und band edu-sharing als föderierte Suche an.
Mehr Infos zum Projekt können in dieser Präsentation → gefunden werden.
Statistikservice für ILIAS
Uwe Kohnle hat begonnen ILIAS um eine Visitenkarte zu erweitern. Der Statistikservice kann dann zukünftig auch Auskunft über Inhalte von ILIAS Kurse anzeigen (work in progress).
Statistikservice für Memucho
Robert Mischke stellte ebenfalls eine Visitekarte für zur Verfügung, sodass „Memucho“ im Statistikservice auftaucht. Außerdem erweiterte er die API und schaffte somit die Grundlage, dass „Memucho“ föderiert durchsucht werden kann.
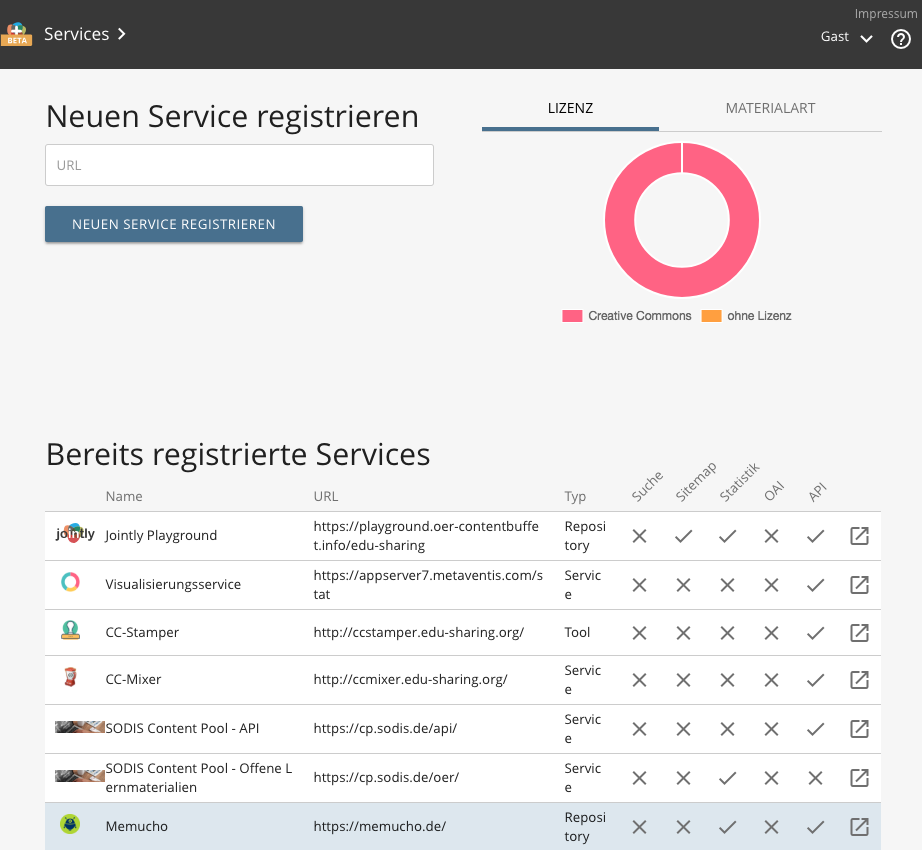
Föderierte Suche von Memucho in edu-sharing
Steffen Hippeli erweiterte den OER Playground um eine weitere Suchquelle. Jetzt wird auch Memucho föderiert durchsucht und Inhalte gefunden.
LRMI und Anbindung an Statistikservice für edutags
Hermann Schwarz vom Deutschen Bildungsserver zeichnete „edutags“ mit LRMI Metadaten aus, sodass Inhalte von Suchmaschinen gefunden werden können. Außerdem legte er die Grundlage dafür, dass „edutags“ im Statistikservice auftauchen kann (work in progress).
Entwicklungsthemen (Workshop 5)
Teil 1) Austausch über zukünftige Entwicklungsthemen
In einer großen Runde kamen IT Experten und Projektmanager aus verschiedenen Ländern und Organisationen zusammen, um wichtige Entwicklungsthemen für die nächsten 1-2 Jahre zu sammeln und sich abzustimmen. An einer großen Wand mit vielen bunten Zetteln wurden Ideen aufgenommen und zu Themengebieten geordnet.

Teil 2) Brainstorming: Was ist die perfekte Autorenumgebung?
Der Fokus lag dann auf der Autorenumgebung. Im Brainstorming-Verfahren wurde zusammengetragen, was alles eine “perfekte Autorenumgebung” ausmacht, welche Bestandteile und Anwendungsfälle dazugehören. Die Autorenumgebung wurde in drei Bereich aufgeteilt:
Editieren & Tool-Anbindung
In der Autorenumgebung sollte es einen Button “+ NEU” geben, der den Nutzenden neben dem Hochladen von Inhalten v.a. Tools und Services anbietet, die geeignet sind um Inhalte kollaborativ zu erstellen und zu bearbeiten aber zentral zu speichern. Es wurden die interessantesten Tools gesammelt: H5P, ONLYOFFICE, Tutory, GeoGebra und Etherpad wurde mehrfach genannt. Auch die Möglichkeit hier direkt einen neuen moodle-Kurs zu erstellen wurde gewünscht.
Dateiverwaltung
In einer Autorenumgebung sollte es außerdem eine einfache Möglichkeit der Dateiverwaltung geben. Inhalte sollen hochgeladen, sehr einfach freigegeben und in Sammlungen verwaltet werden können. Alle erweiterten Funktionen, wie Workflow-Prozesse, differenzierte Freigaben und Berechtigungen sollen in eine eigene Redaktionsumgebung bzw. einen eigenen Modus ausgelagert werden, um die Bedienung nicht zu komplex werden zu lassen.
Redaktion & Review-Prozesse
In dieser Ungebung bzw. in diesem Modus sollen alle erweiterten Funktionen zur Dateiverwaltung und Qualitätssicherungs-Prozessen zu finden sein. Es sollte pädagogische, lizenzrechtliche und metadaten-technische Reviewprozesse geben, eine Möglichkeit der erweiterten Datei-Organisation und Freigabe-Funktionen, Metadaten- und Lizenzierungsangaben.

Teil 3) Abstimmung von Review-Prozessen in den Ländern
Aus dem Themengebiet der “perfekten Autorenumgebung” wurden sich dann die Review-Prozesse in Rheinland-Pfalz, Bayern und Berlin-Brandenburg genauer angeschaut. Ziel der Abstimmung war es 1. die Prozesse in den Ländern zu verstehen und 2. daraus einen ersten Standard-Prozess abzuleiten, um einen länderübergreifenden Austausch zu ermöglichen. Diese Prozesse sollen im Nachgang mit weiteren Ländern abgestimmt und überarbeitet werden.
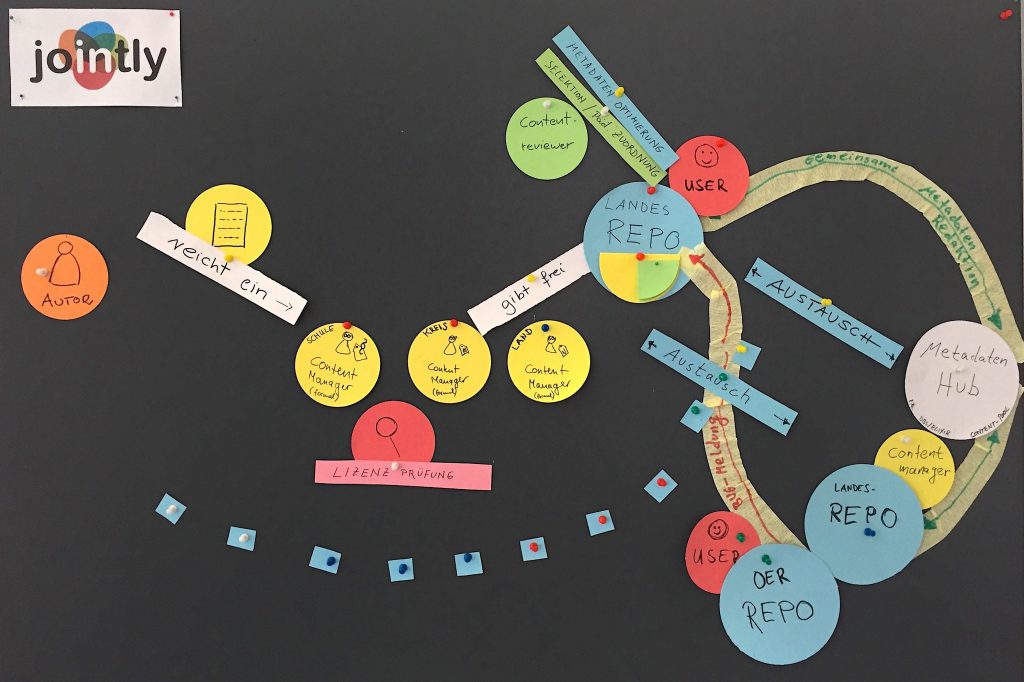
- Ein Autor (kann auch ein Lehrender sein) reicht ein Material ein
- das eingereichte Material kann direkt für die Schule freigegeben werden
- soll das Material für alle Lehrer im Land freigegeben werden, muss eine Lizenzprüfung durch einen Content-Manager stattfinden
- Content-Manager sind auf Landesebene tätig, können aber auch auf kommunaler- oder Schulebene tätig sein
- der Content-Manager gibt Inhalte mit der korrekten Lizenz für das Land frei
- Content-Reviewer wählen pädagogisch geeignete Materialien aus, optimiert die Metadaten (z.B. Zuordnung zu Fach- und Sachgebiet-Systematiken)
- Content-Reviewer geben optimierte Materialien für die Öffentlichkeit frei
- öffentliche Materialien sind somit qualitätsgesichert und können in den länderübergreifenden Austausch gehen
- externe Nutzer benutzen die öffentlichen, qualitätsgesicherten Materialien
- meldet ein externer Nutzer einen fehlerhaften oder bedenklichen Inhalt, wird das an das entsprechende Eltern-Repo geleitet, der zuständige Content-Manager ist zunächst zuständig, schätzt den Fehler ein und leitet es ggf. weiter. Nach erneut abgeschlossenem Review-Prozess ist der Inhalt wieder öffentlich verfügbar
OER Abgabe-Service
Der Wunsch einen OER Abgabeservice (“OER Klappe”) zu haben ist schon mehrere Jahre alt. Seitdem wurde viel darüber gesprochen. Es entstanden technische und organisatorische Konzepte, wie ein zentraler Abgabeservice aussehen kann, was er funktional leisten muss und wie das mit den Lizenzen und der redaktionellen Pflege der abgegebenen Inhalte aussieht.
Nele Hirsch hat diese Ideen auf dem IT Camp aufgegriffen, mit einigen Teilnehmenden besprochen und als zentrale öffentliche Anlaufstelle – die “Bildungsmaterialspende” umgesetzt. Sie kann hier getestet werden: www.bildungsmaterialspende.de
Nutzende können hier Bildungsinhalte hochladen, nachdem sie eine Lizenz für das Material ausgewählt haben. Optional können weitere Angaben wie Titel, Name des Urhebers, eigene Mailadresse etc. angegeben werden. Nach der Einverständniserklärung wird das Material hochgeladen. Der Nutzende bekommt eine E-Mail, dass der Inhalt hochgeladen wurde und in Prüfung ist. Auch nach abschließender Prüfung wird er benachrichtigt, ob der Inhalt weiter benutzt wird oder von der Redaktion als irrelevant für den Bildungskontext eingestuft wurde.
Eine andere Lösung dieser Idee ist an der JOINTLY OER Demoumgebung als “OER DropOff” installiert. Hier ist der Ansatz der, dass es eine länderübergreifende Redaktion geben könnte, die einschätzen, ob die hochgeladenen Inhalte pädagogisch brauchbar sind und verteilen sie ggf. im Netzwerk weiter. Vorher hat der oder die Hochladende versichert, dass 1) das Material selbst erstellt oder nur offen lizenzierte Inhalte nachgenutzt werden und 2) dass er/sie die Redaktion ermächtigt das Material im Bildungskontext frei zu nutzen. Weitere Angaben zum Material können nach dem Upload optional hinzugefügt werden.
Diese Variante kann hier ausprobiert werden: https://playground.oer-contentbuffet.info/dropoff/